
TL;DR Starting from version 0.8.10.1, LiquidHaskell is available as a GHC Plugin. Paying special attention to support existing IDE tooling led to some non-conventional design choices.
LiquidHaskell is a refinement type checker for Haskell that empowers programmers to express contracts about their programs which are checked at compile time, and it has been a wonderful tool for the community in addition to GHC, when the latter is not enough. LiquidHaskell has been historically available only as a standalone executable which accepted one Haskell file at a time, making the process of integrating it into an existing code base more tricky than it should have been.
In this blog post we’ll explore how we turned LiquidHaskell into a GHC Plugin, and all the challenges we had to overcome along the way.
Introduction
This post is intended as an extended cut of my HIW talk, and it nicely complements Ranjit’s more practical blog post. We won’t cover here what LiquidHaskell (LH for brevity) can bring to the table on top of GHC’s type-level programming, as there are plenty of resources out there to get you excited: we recommend starting from the book for a practical motivation on why LiquidHaskell even needs to exist. The official website also covers a lot of material.
What we will do instead is to briefly recap how LH looks like, as well as presenting its internal architecture. After that, we will take a look at the old version of LH in order to understand its shortcomings, and how the plugin helped overcoming those. Last but not least we will explore the iterations of the various designs of our plugin.
A Liquid Haskell “hello world”
If you have never seen how LiquidHaskell looks like in practice, let’s assume we want to check
(i.e. refine) a Haskell module, say A.hs. The content of A.hs is not important, but as an
example let’s suppose it to be:
module A where
import B
import C
{-@ safeDiv :: Int -> {y:Int | y /= 0 } -> Int @-}
safeDiv :: Int -> Int -> Int
safeDiv = divThe first line of the code block, which looks like a Haskell comment with additional @s, is a
Liquid Haskell annotation. All Liquid Haskell instructions are written in special Haskell comments
like this. This particular one assigns a refined type to safeDiv, and it’s essentially enforcing that
the second Int we pass to safeDiv should not be 0. The {y: Int | y /= 0} also shows quite succinctly
the essence of a refinement type, i.e. a type with a logical predicate attached to it. Now, if we try
to attempt a division by 0, for example by calling safeDiv 3 0, LH would reject our program with a big
red UNSAFE printed on screen, while if all is well a nice green SAFE would be shown.
Users can provide such annotations in a number of ways; they can annotate directly the Haskell source files,
like in the example, or they can put all their refinements into a separate .spec file. Doing both
at the same time (for the same module) is also supported, as LH will ensure that all these refinements
will be merged into a single data structure, as we will see below.
LiquidHaskell’s architecture
Before deep-diving into any other section, let’s take a brief detour to explain how LH internally works, as it will help clarify some concepts later on. As usual, a picture is worth 1000 words:

Let’s break down this picture bit by bit. The first thing that LH does is to parse the annotations from
the input file (A.hs) and from the companion .spec file (if any, thus the dashed lines in the picture),
converting everything into a richer data structure known as a BareSpec.
Think of the BareSpec as your input program, that has yet to be compiled: by this analogy, a BareSpec
might still be ill-defined as it’s not yet being checked and verified by LH. Once a BareSpec gets verified
by LH it becomes a LiftedSpec; the intuition behind the name is that the relevant Haskell types have been
“lifted” into their refined counterparts.
Since A.hs imports some other modules, it has a number of dependencies that LH needs to track.
The details are not important at this stage, as this dependency-tracking differs between the executable and
the GHC Plugin, so let’s treat this process as a black box. The end result is a HashSet of LiftedSpec,
where the use of LiftedSpec indicates that dependencies will have been verified (and lifted) by
LH first.
The last piece of the puzzle is the list of Core bindings for A.hs.
Core is GHC’s internal representation, with an AST that is smaller and easier to work with than the full
source Haskell AST. LH desugars the program into Core, transforms it
into A-normal form, then traverses it to generate a set of
refinement constraints that must be solved to “lift” a BareSpec into a LiftedSpec.
The key takeaway is that LH needs access to the Core bindings of the input program in order to work.
Finally, once we have everything we need, LH will apply a final transformation step to the input
{dependencies, coreBinds, bareSpec}, producing two things as a result:
- a
LiftedSpec, which can now be serialised on disk and used as a dependency for other Haskell modules; and - a
TargetSpec, which is the data structure LH uses to verify the soundness ofA.hs.
After creating the TargetSpec LH has to solve what is, effectively, a constraints problem: it generates a
set of Horn Clauses from the TargetSpec and feeds them into
an SMT solver.1 If a solution is found,
our program is SAFE, otherwise it is UNSAFE.
The old status quo
Historically LH has been available only as a standalone executable, which had to be invoked on one or more target Haskell files in order to do its job. While this didn’t stop users from using it for real world applications, it somewhat limited its adoption, despite packages such as liquidhaskell-cabal attempting to bridge the gap.
Compiling Haskell code
Now that we know how the kernel of LH works, understanding the executable and its limitations is not hard; in a nutshell, the executable used the GHC API to accomplish all sorts of tasks: from dependency analysis down to parsing, typechecking and desugaring the input module. Astute readers might argue that this is replicating what GHC normally does, and they would be correct! One of the main shortcomings of the old executable was indeed that there was very little or no integration into GHC’s compilation pipeline.
Writing and distributing specifications
As we have seen already, LH checks each and every refinement it can find while parsing an input Haskell module,
which means that the more refinements we have, the more useful LH will be at spotting bugs and mistakes.
However, this also means that somehow we need to have a way to write and distribute specifications for
existing Haskell types, functions and even packages, as users would not like to be obliged to define
refinements for basic things like + or natural numbers.
The LiquidHaskell HQ stoically solved this problem by shipping a “hardcoded” prelude as part of
the executable, that contained specifications for some types in base and for some preeminent Haskell packages
like containers, bytestring etc. While this worked, it wasn’t very flexible, as it was a “closed”
environment: new specifications couldn’t be added without releasing a new version of LH, not to talk about
tracking breaking changes to the relevant upstream packages. To say it differently, the hardcoded prelude made
a best effort to be compatible with such Haskell packages, but it couldn’t guarantee that newer releases of, say,
bytestring, wouldn’t break the specifications making LH compatible with bytestring-x.x.x.x but not
bytestring-x.x.y.y.
IDE support
With LH available as an executable, there was little hope to integrate it with things like ghcide, ghcid
or even ghci. IDE support was added in an ad-hoc fashion by providing the executable with a --json flag
that could be used to output the result of the refinement (including errors) in a JSON format. One could
then write wrappers around it to turn such JSON into formats editors or LSP servers could understand.
A notable mention goes here to Alan Zimmerman, who added a
haskell-ide-engine plugin
for LH using the limited --json interface, nevertheless creating a very pleasant IDE experience.
The new way
Starting from version 0.8.10.1,
LH is available as a GHC Plugin, which means
that integrating it into your project is as easy as adding an extra -fplugin=LiquidHaskell to the list
of ghc-options in your .cabal file, and adding liquidhaskell and liquid-base to its dependencies.
In the rest of this post we will discuss the design of this plugin, as it ended up being outside the
conventional boundaries of what it can be defined a “standard” plugin, for reasons which will become obvious
later on.
A GHC Plugin quick recap
Before discussing the plugin’s design, let’s quickly recap how a GHC Plugin works, starting, as always, from a picture:
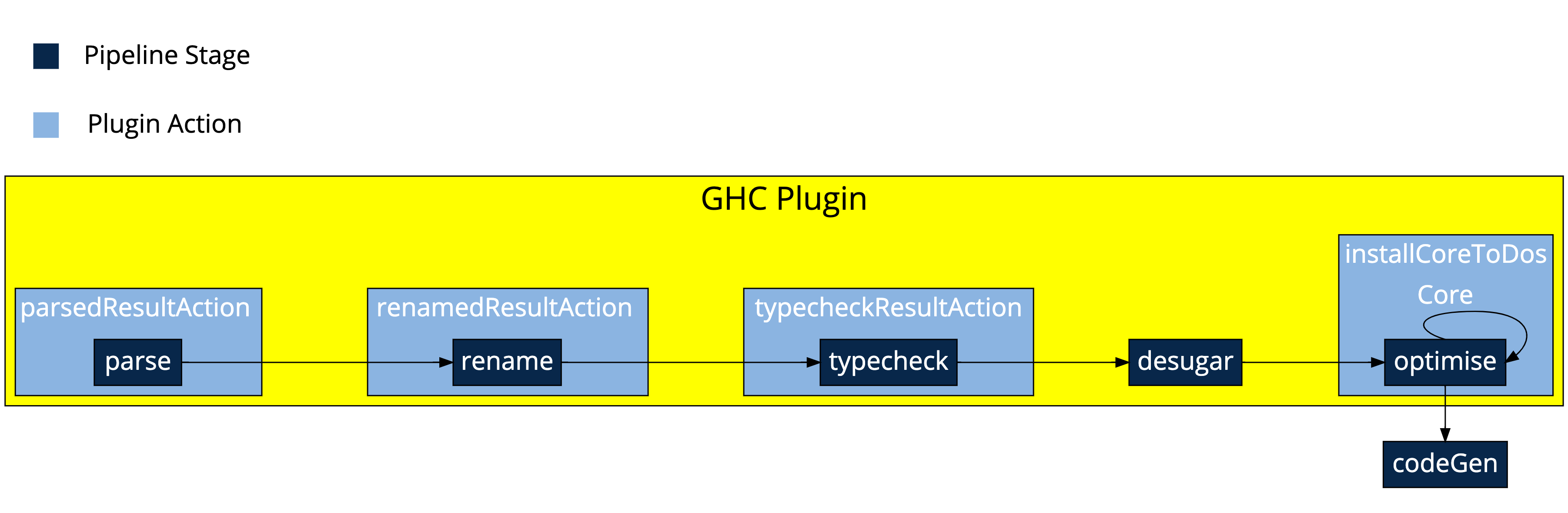
At its core, a Plugin is simply a Haskell data record where record fields expose customisable actions
that can modify most of GHC’s pipeline stages. Let’s take for example parsedResultAction:
parsedResultAction :: [CommandLineOption] -> ModSummary -> HsParsedModule -> Hsc HsParsedModuleThe documentation states that it will “Modify the module when it is parsed. This is called by HscMain
when the parsing is successful.”. This means that we can write a simple Haskell function
that takes as input a HsParsedModule and it has to produce a new HsParsedModule, effectively allowing
us to modify how the GHC pipeline behaves. Similarly, typecheckResultAction is called after typechecking
has ended, while installCoreToDos allows us to add extra optimizations and transformations on the Core representation of the program.
This is for example how inspection-testing performs
its magic, by grabbing the Core bindings at this stage.
The general design idea
There is a fil rouge in all the different iterations of the plugin, namely the idea that a LiftedSpec
should be serialised into the interface file of the associated Haskell module. Doing so is possible
by the virtue of the Annotations API
that the ghc library exposes, and has a number of practical consequences. First of all, it strengthens
this intuition that a LiftedSpec is the primary output of the refinement process and, as such, it’s worth
caching and storing somewhere. Secondly, it allows the plugin to deserialise it back when resolving the
dependencies of the module GHC is currently compiling without resorting to hidden system folders. Most
importantly, it paves the way to distributing specifications, as now the plugin can fetch a LiftedSpec
for a module which doesn’t belong to the HomePackageTable
for that package. This is delegated to the SpecFinder
module, which I have wittily named after the Finder module
in the GHC API.
First attempt: proper pipeline split
Considering all the above, a natural way of designing the plugin could be the following:
- Parse any LH specification during the
parsestage, using theparsedResultActionhook to produce aBareSpec; - Perform any name resolution needed by LH in the
typecheckResultAction, and store the result somewhere; - Add an extra
Corepass in theinstallCoreToDosthat grabs the[CoreBind], performs the ANF transformation and finally calls the LH API to check the result.
This was the first design I explored when working on the first prototype. Due to the fact that there is no
good story for passing plugin state between phases, I had to resort to either serialise something as an
Annotation in order to retrieve it back in a different stage, or more pragmatically use an IORef,
typically wrapping something like a Map Module MyState.
Challenge: Unboxed types
The first iteration of the plugin worked, until I tried to refine a program which looked a bit like this:
module Challenge1 where
{-@
data BBRef = BBRef
{ size :: {v: Int | v >= 0 }
}
@-}
data BBRef = BBRef {
size :: {-# UNPACK #-} !Int
-- ^ The amount of memory allocated.
}
-- ... do something with BBRefOne aspect of LH we didn’t talk about is the ability to refine data structures, like in the example. Unfortunately, this made me discover a hard requirement I didn’t anticipate: LH needs access to the unoptimised core bindings.
What does this mean, exactly? It means that LH’s output can’t depend on the optimisation level of the
user’s program. In other terms, a plugin would inherit the same optimisation level the user requested when
kicking off a GHC build, but LH strictly requires it to be -O0. More specifically, if we take size as
an example, LH requires the relevant Int to be boxed, because it needs to “match it” with the Int in
the refinement, but UNPACK changes all of that, effectively producing a type mismatch and causing LH to
fail with a ghastly error.
Final design: duplicate work, reduce the plugin surface
Back to the drawing board, we decided to bite the bullet and accept the fact that we simply can’t control the
optimization level; not in the practical sense, as the GHC API allows you to modify the level in
the global DynFlags, but in a semantic one: it would have been wrong to sweep the rug under users’ feet
that way. Imagine trying to compile an executable meant for production just to discover with horror that a
plugin silently changed the optimisation level to be “debug”.
Since LH requires the program to be compiled with -O0, but the user might well
be compiling with -O1 or higher, we will inevitably need to duplicate some
stages of the compilation pipeline.
Initially I tried to solve this problem by “manually” calling typecheckModule and desugarModule using
the GHC API inside the installCoreToDos action run after desugaring. Unfortunately it turns out to be necessary to replicate
even the parsing stage, with a call to parseModule.2 Since the
pipeline split wasn’t enforced so strictly anymore, we ended up moving all the plugin logic into
typecheckResultAction,3 with the added bonus that no intermediate state-passing was needed anymore.
This is, to this day, the design we settled for.
This has the unfortunate consequence that we are now doing most of the work twice, but I hope this could be fixed in future versions of GHC, for example by allowing plugins to run even earlier in the pipeline or by having the unoptimised core bindings cached somewhere.
While the duplication of work is admittedly somewhat unsatisfactory, it is still no worse than running
the standalone liquid executable in addition to GHC itself. With this design, we effectively recovered feature
parity with the old binary. As an added bonus, it meant that ghci worked out of the box.
Supporting ghcid required only a bit more effort, namely emitting warnings and errors in the
same format
used by GHC, and making sure that LH strictly abided to this format everywhere in the codebase.
Finally, after patching a few more bugs (discussed in the appendix), even ghcide worked as expected:4
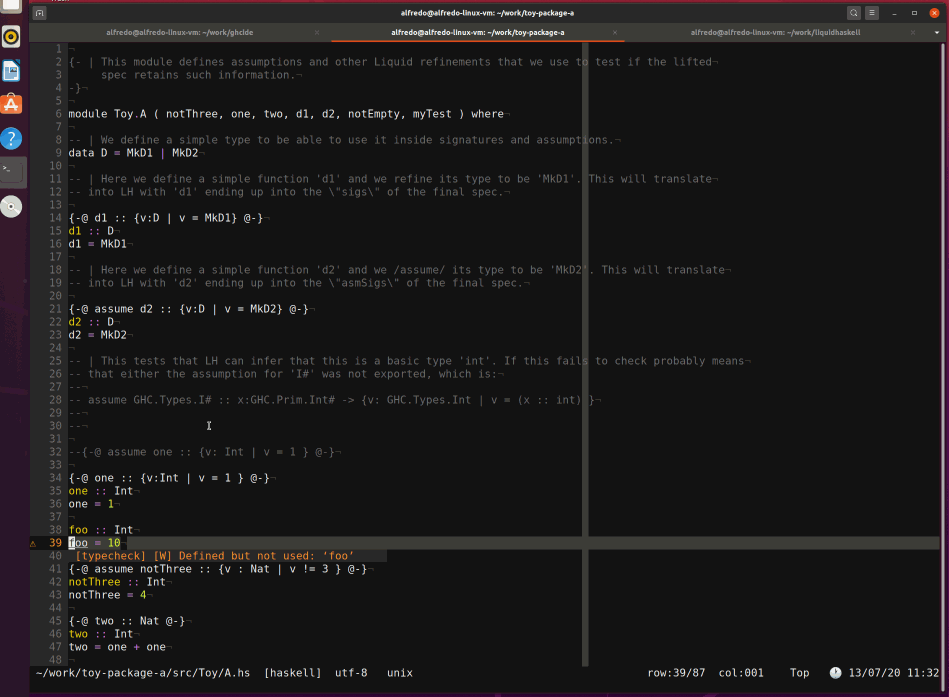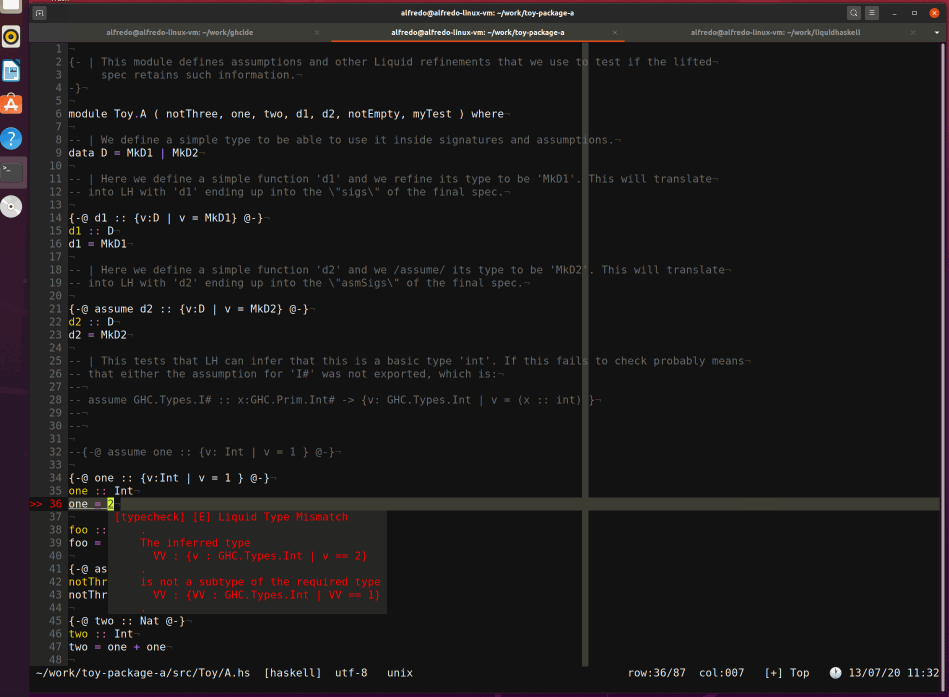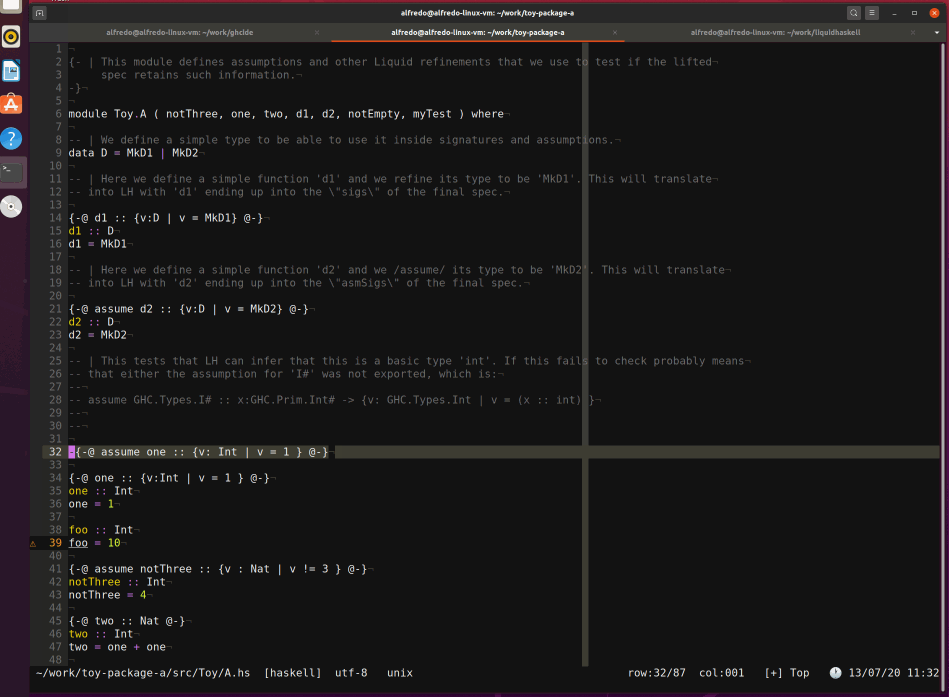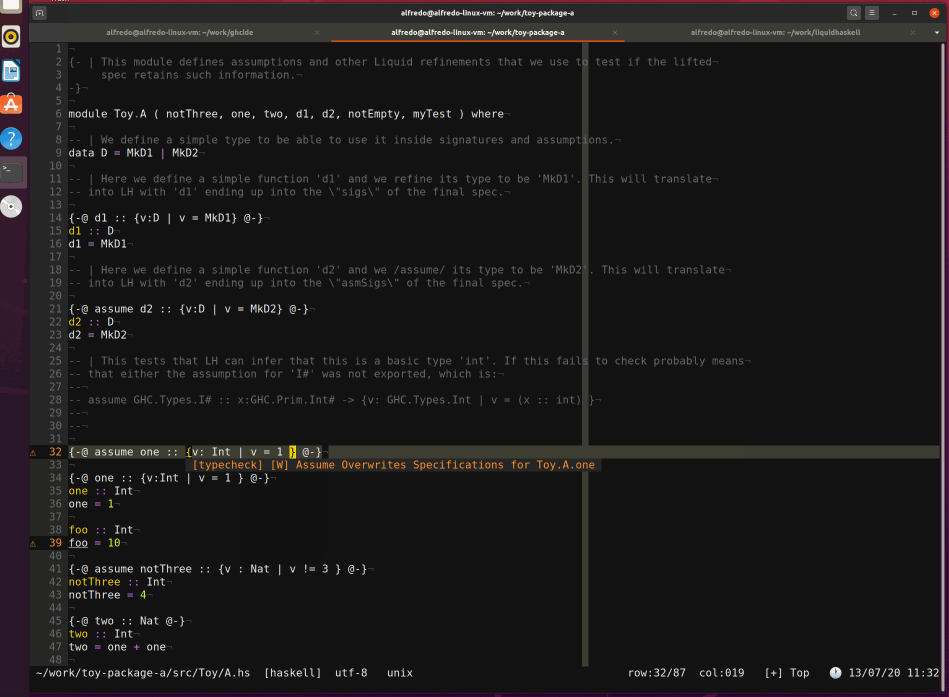
What about the ecosystem?
We haven’t yet discussed the package ecosystem for LH, or how users can contribute specifications to existing packages. One of the goals for the project was specifically to empower users to extend LH’s ecosystem using familiar infrastructure (e.g. Hackage, Stackage, etc).
We have seen how serialising a LiftedSpec into an interface file solved the technical problem, but it left
us with a social problem: what to do about “preeminent” Haskell packages we would like to refine? By “preeminent”
I mean all those packages which are really in the top percentile in terms of “most used”: think base,
vector, containers and so on. Typically their development speed is not very fast-paced as these
are part of the backbone of the Haskell ecosystem, and getting new changes in is quite hard, or requires
careful thinking.
While adding LH annotations directly into these packages wouldn’t break anything, it’s surely something which needs to be motivated and, ultimately, maintained, so it might not be easy to make it happen over a short period of time. This is why we opted for a different approach: instead of trying to patch these packages we released “mirror” packages: They trivially re-export all the modules from the mirrored package while also adding all the necessary refinements.
At the moment of writing, we offer drop-in replacements for a handful of packages:
Users willing to write specifications for their existing packages can either adopt this mirrored-package approach or integrate LH specs directly into their Haskell code, and both approaches have pros & cons. In particular, integrating LH specs directly into an existing package means a tighter coupling between the Haskell and LH code, so the package author will be responsible for making sure that LH specs stay compatible with multiple versions of Liquid Haskell when they are released. That is, package authors adopting this approach have to worry that their packages work for new versions of GHC as well as new versions of LH (although the latter is typically released in a lockstep fashion with GHC).
For a more “hands-on” introduction, check out Ranjit’s blog post, specifically the “Shipping Specifications with Packages” section.
Managing and tracking versions
Once again, the astute readers might be wondering how to track changes to the mirrored packages. While getting the recipe right is tricky, we propose a simple PVP scheme, in the form of:
liquid-<package-name>-A.B.C.D.X.YA.B.C.D tracks the upstream package directly, while X.Y allow for LH-related bug fixes and breaking changes.
As a practical example, let’s imagine some users wishing to add specifications to an existing package acme-0.1.2.3.
Those users would release a liquid-acme-0.1.2.3.0.0 adding whichever specification they like. In case acme-0.1.2.4 is released,
they would also release liquid-acme-0.1.2.4.0.0, and in case they discovers a bug in one of the
existing specifications for acme-0.1.2.3 then a liquid-acme-0.1.2.3.0.1 could be released. The penultimate
digit is reserved for changes to the LiquidHaskell language. This way, if the refinements for acme now
relies on a new shining LH feature, our users would release something like liquid-acme-0.1.2.3.1.0 to
reflect that.
While not perfect, this scheme should work for the majority of cases.
Trade-offs
Needless to say, this approach of mirroring packages only to add specifications is not perfect.
First of all, keeping track of all the different versions of all these packages and following their release
schedules adds inevitable overhead. The LH codebase provides some scripts to mirror modules fairly easily,
but some human intervention is needed in case of API changes. Furthermore, now a package wishing to use
LH would have to depend on liquid-base but not base, which might not be an option for some projects,
or not something projects would like to commit to immediately, just to try out LH. On the bright side, now
it is possible to distribute specs independently of the underlying package, without having to burden the
primary maintainer.
Ultimately this would have been a very nice use case for Backpack, but that would require
substantial work, not to mention that tools like stack don’t support Backpack yet.
Conclusions
Working on this GHC Plugin was interesting and challenging for me, and I hope that with the plugin Liquid Haskell will get the adoption it deserves.
It is tricky to reconcile plugins that modify the GHC pipeline with tools that
act on the frontend (like ghcide), mostly due to the low-level nature of the GHC API. Not having access to
a more “pure” way of accessing the unoptimised core binds complicated the plugin design, and I hope in the
future we will be able to mitigate this also to make the whole plugin more efficient by avoiding expensive
operations, like parsing or typechecking each module again. Another thing which I would love to see in future
GHC API releases is a good story for passing around state between different plugin actions: eventually
I didn’t need any state due to the fact I was forced to write everything into a single plugin action, but
during “First attempt” this was a pain I had to deal with. From a social perspective it will be fascinating to
see how the choices we made on the mirror packages will work out for the community.
Acknowledgements
I would like to thank Ranjit Jhala and Niki Vazou for all their support, from answering all our endless questions down to hand-holding us through the Liquid Haskell internals, speeding up our work several orders of magnitude.
Thanks also to UCSD and to the NSF for funding this work under grant 1917854: “FMitF: Track II: Refinement Types in the Haskell Ecosystem”.
Appendix: supporting ghcide
Having our plugin called by ghcide was not enough unfortunately, as the output reported by ghcide was
not correct. We tracked this not to be ghcide’s fault, but rather GHC issue #18070
which GHC HQ kindly patched and released as part of 8.10.2.
Armed with a patched GHC, I finally tried ghcide again, but surprisingly enough diagnostics were emitted
(at least from nvim) in a delayed fashion, typically only when the file was saved. This is a suboptimal
experience: after all what makes ghcide so compelling is the ability to get diagnostics almost in real time,
while editing the buffer. Another debugging session revealed a bug in ghcide, which deserves an honorable
mention in this appendix.
In order to understand the problem, we have to briefly explain what is a ModSummary.
A ModSummary is a key component of the GHC API, and is described by the documentation as a “single node in a ModuleGraph”.
This type is used pervasively by the GHC API, and is an input argument to the parseModule function, that we
ended up using in the final design to parse each module.
A ModSummary has a number of fields, but we’ll focus only on two of them:
data ModSummary
= ModSummary {
...
ms_hspp_file :: FilePath,
, ms_hspp_buf :: Maybe StringBuffer
...
}The former is the path on the user’s filesystem of the associated Haskell module, whereas the latter is
the preprocessed source. What’s even more important is that parseModule would look first at the
ms_hspp_buf to see if we have a “cached”, already-parsed module to return, or it would otherwise parse the
module from scratch accessing it at the ms_hspp_file path.
The essence of the bug was that ghcide was constructing a ModSummary out of thin air,
but it wasn’t correctly setting the ms_hspp_buf with the StringBuffer associated to the current
content of the file, which meant that our plugin was able to “see” changes only when the file was saved and
the new version of a module was available on disk, but not any sooner.
Luckily for us the fix was easy, and the ghcide devs kindly accepted our PR.
After shaving this fairly hairy yak, things worked as expected.
Therefore, LH depends on an external theorem prover such as Z3.↩︎
In particular, a
typecheckModuleaccepts aModSummaryas input, which contains the cachedDynFlags, so it’s possible to temporarily create a copy of the globalDynFlagswith optimisations turned off. Unfortunately, this wasn’t enough for theUNPACKcase, because apparentlyUNPACKgets “resolved” during parsing, which means that by type-checking time it was already too late to switch off optimisations that way.↩︎Why did we choose
typecheckResultAction, rather than sayparsedResultAction? This is crucial for supporting integration withghcide. Note thatghcideuses the GHC API as well, but crucially it runs the typechecking phase, not earlier phases. To put it differently, the GHC API would call any registered GHC Plugin at this point, but it would call only thetypecheckResultActionhook, which meant the parsing phase is completely bypassed.↩︎The screenshot above used
ghcide-0.2.0with my patch cherry-picked on top, and compiled againstghc-8.10.2, so unfortunately YMMV.↩︎