
The large-records library provides support for large records in Haskell with
much better compilation time performance than vanilla ghc does. Well-Typed and
MonadFix are happy to announce a new release of this
library, which avoids all Template Haskell or quasi-quote brackets. Example:
{-# ANN type User largeRecordLazy #-}
data User = MkUser {
name :: String
, active :: Bool
}
deriving stock (Show, Eq)
instance ToJSON User where
toJSON = gtoJSON
john :: User
john = MkUser { name = "john", active = True }
setInactive :: User -> User
setInactive u = u{active = False}This makes for a nicer user experience and provides better integration with tooling (for example, better syntax highlighting, auto-formatting, and auto-completion). Importantly, avoiding Template Haskell also means we avoid the unnecessary recompilations that this incurs1, a significant benefit for a library aimed at improving compilation time.
In this blog post we will briefly discuss how this was achieved.
Avoiding quotation
Record declaration
The previous large-records version used quotation in two places. First, it was
using Template Haskell quotes for record definitions, something like:
largeRecord defaultLazyOptions [d|
data User = MkUser {
name :: String
, active :: Bool
}
deriving stock (Show, Eq)
|]The new version avoids this by using a ghc source plugin
instead of TH. The source plugin generates much the same code as the TH code
used to do; if you’d like to see what definitions are generated, you can use
{-# ANN type User largeRecordLazy { debugLargeRecords = True } #-}Record expressions
Record updates such as
setInactive :: User -> User
setInactive u = u{active = False}were already supported by the old version (and are still supported by the new),
since these rely only on RecordDotSyntax as provided by
record-dot-preprocessor. However, record values required
quasi-quotation in the previous version:
john :: User
john = [lr| MkUser { name = "john", active = True } |]Here it was less obvious how to replace this with a source plugin, because we
cannot see from the syntax whether or not MkUser is the constructor of a
large record. Moreover, the old internal representation of large records
(described in detail in Avoiding quadratic core code size with large
records) meant that ghc was not even aware of name or active
as record fields. This means that the source plugin must run before the
renamer: after all, name resolution would fail for these names. This in turn
essentially means that the plugin gets the syntax to work with and nothing else.
The solution is an alternative internal representation of records, after a
cunning idea from Adam Gundry. For our running example, the code that is
generated for User is
data User = forall n a.
(n ~ String, a ~ Bool)
=> MkUser {
name :: n
, active :: a
}This representation achieves two things:
ghcwon’t generate field accessors for fields with an existential type (avoiding quadratic blow-up)- but it still works much like a normal record constructor; in particular,
record values such as
johnwork just fine.
This representation does mean that regular record updates won’t work; something like
setInactive :: User -> User
setInactive u = u { active = False }will result in an error
Record update for insufficiently polymorphic fieldWhen using RecordDotSyntax however all is fine, which was already a
requirement for using large-records anyway.
Performance
The main benchmark for large-records is a module containing a record
declaration with n fields with Eq, Show, Generic and HasField
instances, and a ToJSON instance defined using a generic function. See the
Benchmarks section of the first blog post on
large-records for additional information.
The code generated by the new source plugin is very similar to the code that was
previously generated by TH. Critically, it is still linear in the size of the
record (unlike standard ghc, which is quadratic); see to the full report on
the (compile time) performance of large-records for details. We
therefore don’t expect any super-linear improvements in compilation time; indeed,
improvement of compilation time was not the point of this refactoring (other
than avoiding unnecessary recompilations due to TH). It is nonetheless nice to
see that the plugin is roughly 25% faster than TH:
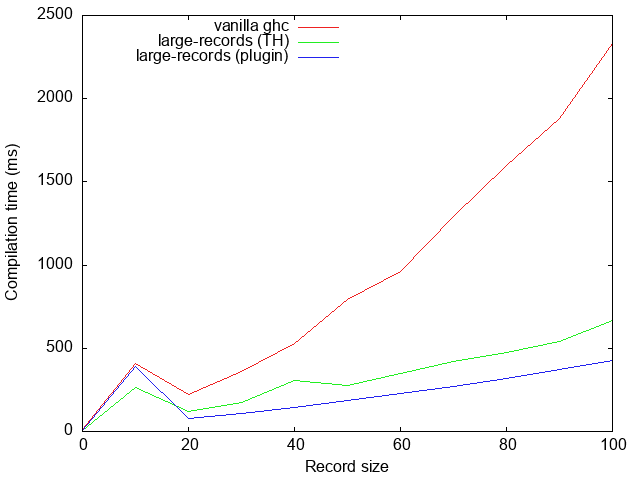
Although we didn’t measure it, avoiding quasi-quotation for record values should also help improve compilation time further, depending on how common these are in any particular codebase.
Conclusions
The large-records library is part of our work on improving compilation time on
behalf of Juspay. We have written extensively about these
compilation time problems before (see blog posts tagged with
compile-time-performance), and also have
given various presentations on this topic (HIW 2021,
HaskellX 2021). This new release of large-records is
not fundamentally different to the previous. It still offers the same features:
- linear-size
ghccode and therefore much better compilation time performance - stock derivation support (
Show,Eq,Ord) Genericssupport (throughlarge-genericsstyle generics, similar in style togenerics-sop)HasFieldsupport for integration withrecord-dot-preprocessor
However, the fact that Template Haskell quotes and quasi-quotation are no longer required in the new version should make for a much better user experience, as well as further speed up compilation time projects with deep module hierarchies.
Suppose module
Bimports moduleA. IfBuses Template Haskell splices, it will be recompiled wheneverAchanges, whether or not the change toAis relevant. Specifically, even with optimizations disabled, a change to the implementation of a function inAwill trigger a recompilation ofB. The reason is thatBmight executefin the splice, andghcmakes no attempt at all to figure out what the splice may or may not execute. We have recently improved this inGHC HEAD; a blog post on that change is coming soon.↩︎