
Haskell projects are organised into packages and components,1 each of which can include many modules (corresponding to source files). Projects are compiled by GHC one component at a time, starting with components that depend only on the standard library and moving through the chains of dependencies until the user’s application or library is reached. Not every component depends on every other component, which means that there are opportunities to build components in parallel. At the same time, GHC is capable of parallel builds within a single component when its modules are independent. This causes a coordination problem: when GHC is building a single component, it cannot use all available parallel hardware without negatively impacting concurrent builds of other components. Before now, multiple GHC processes were not able to coordinate their activities, leading to suboptimal allocation of compute resources.
This blog post explains a new feature for GHC & Cabal, which allows multiple simultaneously running GHC processes to coordinate their use of compute resources. This enables build tools such as cabal-install to spawn multiple GHC processes, each making use of parallelism, without oversubscribing the system. As a result, when compiling many dependencies at once, we can build Haskell packages with much better system-level saturation.
This feature will be available with GHC 9.8 and cabal-install 3.12.
In practice, you can simply pass -j --semaphore
when building with cabal (or include jobs: $ncpus, semaphore: True in cabal.project)
in order to see the benefits (more usage details below).
You can read more about the background in
GHC Proposal #540.
To illustrate the benefits one can see when compiling packages and their dependencies from scratch, we have observed:
- a 22% wall-clock time speedup in compiling
lens(118s vs 152s). - a 29% wall-clock time speedup in compiling
pandoc(556s vs 788s).
In each case this compares cabal build -j8 --semaphore versus cabal build -j8 --ghc-options=-j1.
These are best-case situations for the new feature, where a large package
and many smaller packages are compiled in a single cabal invocation.
In practice, one typically compiles dependencies
a single time before iterating on the main package, in which case the benefits
may be less.
The problem: parallelism between packages vs. parallelism within packages
GHC, when invoked as ghc --make, compiles a single component2
consisting of many modules.
The ghc --make command accepts a -jN option to instruct it to compile up to
N modules in parallel (using up to N OS threads, typically one per core).
Build tools, such as cabal-install and stack,
compute the dependencies of a package, compose a build plan, and execute many
ghc --make subprocesses, first to build the dependencies,
and then the target package itself.
Both cabal-install and stack also accept a -jN option, however the meaning
here is different. It instructs the build tool to build up to N packages in
parallel. Each of those packages will be built by an invocation of ghc --make -j1,
in order to avoid oversaturating the system.
Thus, while both GHC and cabal-install provide ways to parallelise their workloads, these two
mechanisms do not compose well, because of the need to pick separate fixed -j values:
- If the build plan has many small packages, we can use
cabal build -j<N> --ghc-options=-j1, which compilesNpackages at a time, with modules from each package being compiled serially. - If the build plan has a single large package, we can use
cabal build -j1 --ghc-options=-j<N>, which compiles the package in a singleghc --makeinvocation, with GHC compilingNmodules at a time in parallel. - In practice, however, a typical build plan is “wide” in some parts and “tall” in others,
so no single command of the form
cabal build -j<M> --ghc-options=-j<N>is suitable.
For example, a common scenario is building a large application with many small
dependent packages, which themselves may depend on a single large package
containing many modules (e.g. vector). This leads to a build graph like this:

The optimal build strategy here is to assign all cores to building the bottom package. Once that is complete, build all the middle packages in parallel, each on a single core. Finally, compile the top package, in parallel. Crucially, in order to saturate all the cores, we need to be able to dynamically assign a number of cores to compile each package.
The compilation of the “top” package can be especially problematic, as cabal’s
default behaviour is to always use --ghc-options=-j1. This means that the large
application (which could contain hundreds of modules) would be compiled serially,
even though many more cores might be available. Knowledgeable users might
specify --ghc-options=-j<n> manually, but even then the ideal value may differ
depending on whether the application is being compiled alone or along with its
dependencies!
This is one of the most critical shortcomings that the new approach alleviates: once we get to the final “top” package, we can devote all our cores to its compilation, as no other jobs will be competing for resources at that point.
The solution: coordination via semaphores
The solution, described in
GHC Proposal #540,
is to allow the build tool and individual
invocations of GHC to share processor cores. This is done by communicating through
a system semaphore, created by the build tool and passed to GHC using a new command-line flag -jsem <semName>.
When this flag is passed to GHC, the compiler will begin with access to a single
core, but can request more if there is a workload that would benefit from
parallelism.
A system semaphore is a concurrency primitive provided by the operating system. It maintains a count of the number of available resources (in this case, the number of cores). Multiple processes can request resources from the semaphore. These requests will succeed, reducing the count, until the count reaches zero at which point further requests will block. When a process finishes its task, it can signal the semaphore that it has finished with the resources and thereby increment the count, potentially unblocking another waiting process.
By having multiple build processes share a semaphore whose resource count is the number of cores, each process can potentially make use of multiple cores if it has work to do in parallel, but we avoid oversubscribing the system by trying to run more threads than the available cores.
The proposal specifies a concrete protocol for the sharing of parallelism across a system semaphore, to allow different build tools to implement the same mechanism. There are two kinds of participants in the GHC Jobserver protocol, a jobserver (cabal-install) that invokes multiple instances of jobclients (GHC). To understand the protocol in more detail, take a look at the proposal.
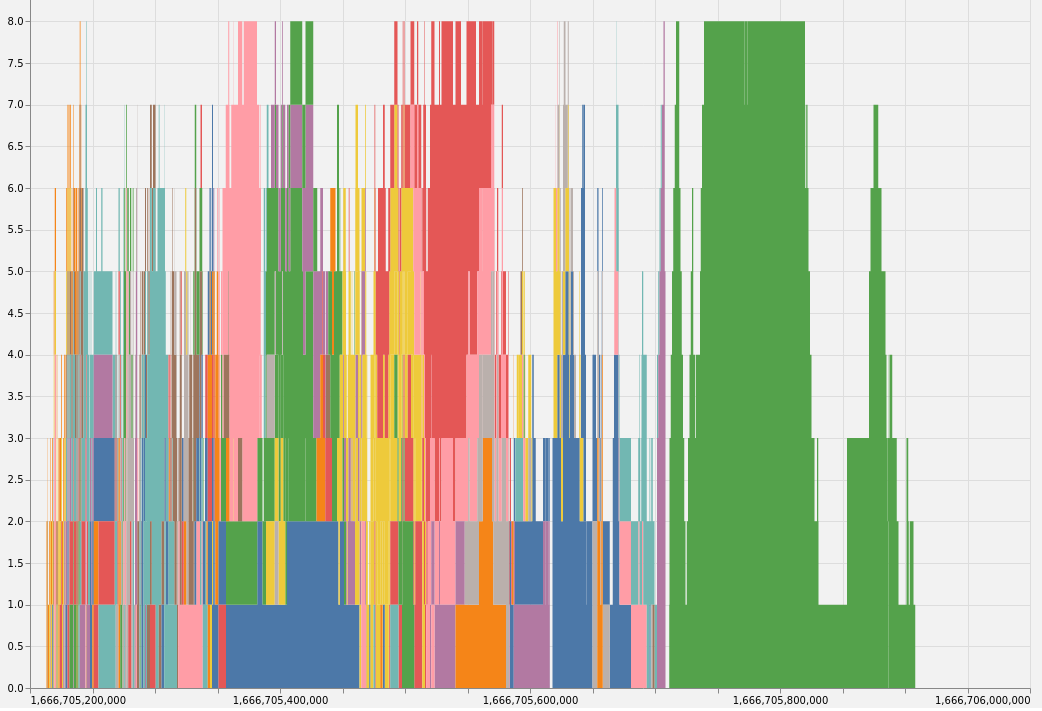
The following graph shows the number of cores in use against time when
building pandoc and all its dependencies. Different packages are represented by
different colours. Observe that while the dependencies are being built, most
occupy a small number of cores and several packages are built in
parallel. Then once pandoc itself starts being built, the cores are
saturated by that single package.
Implementation status
Matthew and Sam added the -jsem flag to GHC and implemented jobclient support in GHC MR !8970, based on earlier work by Douglas Wilson. This will be part of GHC 9.8, which should be released later this year; or you can try GHC 9.8.1-alpha1 now.
Matthew implemented the jobserver in cabal-install, in Cabal PR #8557. This is expected to be part of cabal-install 3.12 which should be released alongside GHC 9.8.
As part of this, we have implemented an abstraction layer for communicating with system semaphores in a cross-platform way in the semaphore-compat package. In particular, this package provides a mechanism for interruptible wait operations on system semaphores. This means jobclients can wait for semaphore tokens when they would benefit from parallelism, but cancel this request for resources if they finish all their work before any tokens became available on the semaphore.
Today, cabal-install is the only implemented jobserver, but Stack would also be a natural jobserver (see Stack issue #6131). GHC is the only jobclient, and there are no concrete plans to implement more, but other CPU-bound build tools would be natural additional clients.
Usage
With GHC (version 9.8 or above) and cabal-install (version 3.12 or above),
you can enable this functionality by passing both the --semaphore flag
and the normal -j option to cabal-install, e.g.
cabal build -j --semaphoreThis will instruct cabal to act as a jobserver. It will create a suitable system
semaphore with one slot per CPU core, which is then passed to each ghc invocation.
The cabal.config or cabal.project equivalent is semaphore: true, alongside jobs: $ncpus.
At the moment, users have to opt in to the new feature explicitly, in case it exposes bugs or undesirable behaviour (e.g. increasing parallelism may have the side effect of increasing memory requirements to build a project). If all goes well, it may become the default in a future release of cabal-install.
Future work
Currently, GHC parallelises builds in --make mode at the module level.
Different modules can be compiled in parallel, but each individual module is
compiled using only one thread. In the future, we want to explore whether
it is possible to increase parallelism when compiling individual modules, by
parallelising specific parts of the module compilation pipeline.
Two possible avenues we want to explore are:
- Adding parallelism to the simplifier.
- Compiling static and dynamic object files in parallel.
These both seem like natural places to paralellise the build further. Then, in situations where either of these two steps takes a long time, we would gain additional opportunities to speed up builds, even when we can’t compile multiple different modules in parallel (e.g. due to a sequential module graph).
We are also working on making wider use of multiple home
units, which allows ghc --make to compile
several packages in a single process, thereby providing better parallelism and
various other advantages. However, it is not always applicable (e.g. if the
build plan involves non-Haskell dependencies), hence the need for the feature
described in this post.
Conclusion
Providing better coordination between GHC processes is a good way to improve build times for large projects:
- Build times when building dependencies should improve, because large packages can be compiled using more cores, so they are less of a bottleneck.
- Normal development build times may be improved, because the “top” package will
be compiled with all cores available by default, rather than requiring users
to manually specify
ghc-options.
This work has been made possible by Hasura. It continues our productive and long-running collaboration on important and difficult tooling tasks which will ultimately benefit the entire ecosystem. Thanks also to Douglas Wilson for his ideas and initial work on this feature, and to David Christiansen for feedback on a draft of this blog post.
Well-Typed is able to work on GHC, HLS, Cabal and other core Haskell infrastructure thanks to funding from various sponsors. If your company might be able to contribute to this work, sponsor maintenance efforts, or fund the implementation of other features, please read about how you can help or get in touch.